
こんにちは、eQOL(イーキュオル)の山下です。
ChatGPTなどの大規模自然言語モデル(LLM)の性能向上が著しいですよね。ChatGPTはGPT3.5やGPT4といった事前学習済みのAIモデルを対話用にファインチューニングして構築されたモデルです。事前学習では1000億を超えるパラメータを最適化する膨大な計算がなされていて、もはやちょっとした大企業でも手を出せない領域になっています。
しかし安心してください。事前学習済みモデルは、人類共有の知的財産をとてもシンプルな戦略で学習したものであり、その成果物である事前学習済みモデルはオープンソースとして利用できるようになっています。この事前学習モデルは優秀な中高生レベルには賢いのですが、大人のマニアックな要求に十分に答えるにはさらに専門的に大学や社会で学んでいくことが必要なわけで、我々一般人がなすべき(我々のできる)ことは特定のタスク用にLLMをファインチューニングし活用することであると言っても過言ではないと思います。というわけで、このブログではLLMのファインチューニングを自分で手を動かして挑戦してみたい、という人向けに記事を書いていきたいと思います。
前置きが長くなりましたが、まず今回はPEFT(Parameter-Efficient Fine-Tuning)について解説していきます。この記事を書くにあたっては、以下のブログを参考にさせていただきました。ありがとうございます。
ちなみに、PEFTの対義的な方法はFull Fine Tuning(Full FT)です。これは、事前学習で最適化した全パラメータをFT用のデータに対して再学習する方法です。理解しやすい考え方ですが、この方法には(特に一般人の我々には)以下のような致命的な問題があります。
- 膨大な計算コスト
- 壊滅的忘却(せっかく学習したことが台無しになる)リスク
- 少ない新しいデータに対して過学習しがち
- ファインチューニングしたモデルも巨大なので保存・管理・活用が大変
このような問題を解決するためにPEFTと呼ばれる手法が提案されています。
PEFTとは何か?
- 一部のパラメータだけをファインチューニングするアプローチ
- 計算コストを削減つつ、優れた汎化性能を獲得可能
- PEFTのアプローチは大きく3つに分類可能
- トークン追加型
- Adapter型
- LoRA型
以下、PEFTのアプローチについてみていきます。以下の解釈は、著者なりに理解したものですので間違いがあったらぜひ指摘していただきたいと思います。
・トークン追加型
トークン追加型は、事前学習済みモデルのパラメータは凍結して、入力層(ChatGPTでいうプロンプト)に仮想トークンを追加してその仮想トークンを特定タスク(ファインチューニングデータ)に対して最適化する方法です。プロンプトエンジニアリングと言ってプロンプトを工夫することで特定タスクを解くアプローチがありますが、これはその戦略と同じでプロンプトに追加するトークン(入力文章)自体を学習してしまおう、というアプローチではないかと思います。トークン追加型はその方法がいくつか提案されており、Prefix Tuning、P Tuning、Prompt TuningのアプローチがHuggingFaceに紹介されています。
・Prefix Tuningのアプローチ

・Prompt Tuningのアプローチ

・Adapter型
Adapter型は、Multi-Head-Attention層とFeed-forward層の出力を入力として受け取って、新たな出力をする追加の層を挿入する方法です。事前学習したパラメータは変更せず、新たに挿入したAdapter層のパラメータのみをファインチューニングで最適化します。
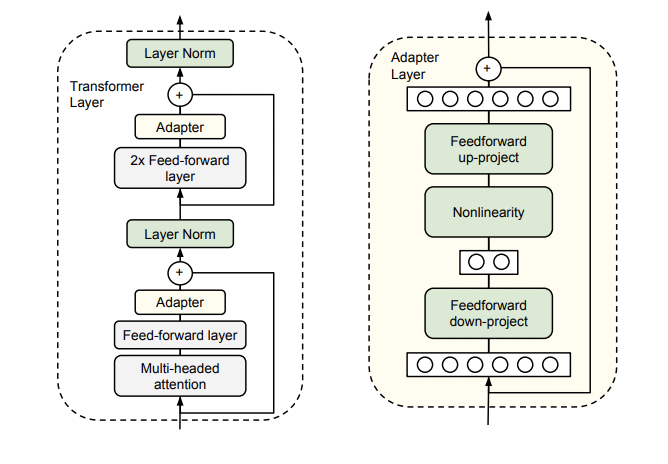
・LoRA型
実は、この以下の内容を理解しきれていないので、以下は参照元の文章をそのまま掲載しています。ご容赦ください。もう少し理解が深まったら私の言葉で解説をしていきたいと思います。
LoRA(Low-Rank Adaptation)は、事前学習済みモデルのAttention層のクエリとバリューに対して、低ランク行列を適用することで、パラメータ数を大幅に削減しながら、元のモデルと同等かそれ以上の性能を達成する手法です。具体的には、下図のように事前学習済みモデルのパラメータを凍結した上で、クエリとバリューの行列に対して低ランク行列を掛け合わせて新たな行列を作ります。この低ランク行列は、ファインチューニング時に学習される唯一のパラメータとなります。
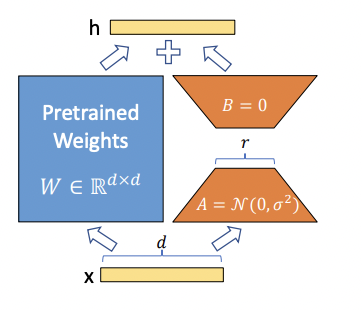
LoRAは事前学習済みモデルの99.9%以上のパラメーターを凍結した上で新しいタスクを学習するために低ランク行列のみを更新しています。これによりFull FTと同等の性能を実現する一方で、パラメータ数と計算要件を大幅に削減することに成功しています。
Adapter では、事前学習済みのモデルにトレーニング可能なパラメーターが追加されるため、推論の待ち時間が長くなる可能性がありましたが、LoRAでは、トレーニング可能な低ランク行列が事前学習済みモデルの各層に注入され、推論中に凍結された重みと更新された重みをマージできるため、推論の遅延が発生しにくくなります。
LoRAを用いることで、計算リソースとストレージコストがシビアとなる本番環境において、LLMをデプロイしやすくなります。
大きな有用性のあるLoRAですがいくつか課題も指摘されています。
変換した低ランク行列が元のモデルの表現力をある程度損なう可能性がある点やパラメータの更新が元の事前学習済みモデルに依存しているために、その事前学習済みモデルの性能と制限事項を受け継ぐ点が課題として指摘されています。
・PEFTの実践
次回のブログにて、日本語のLLMとして利用可能なrinna/japanese-gpt-neox-3.6bをファインチューニングする手法について具体的なコードで紹介していきたいと思います。そこでは以下のブログを参考にLoRAのアプローチでのファインチューニングを解説していきます。
