こんにちは、eQOL(イーキュオル)の山下です。
36億パラメータの日本語LLMのRinna-3.6BをLoRAファインチューニングする方法を紹介したブログを参考に、「天空の城ラピュタ」のシータのセリフを学習させることを試みました。
Google Colab で Rinna-3.6B のLoRAファインチューニングを試す
元ブログでは、Hugging FaceのDatasetsで使えるkunishou/databricks-dolly-15k-jaを使ってファインチューニングをしていますが、このブログではオリジナル(?)のDatasetを用意してファインチューニングしてみます。
ファインチューニング用データ
GoogleのSpreadsheetに次のようなデータを作成しました。
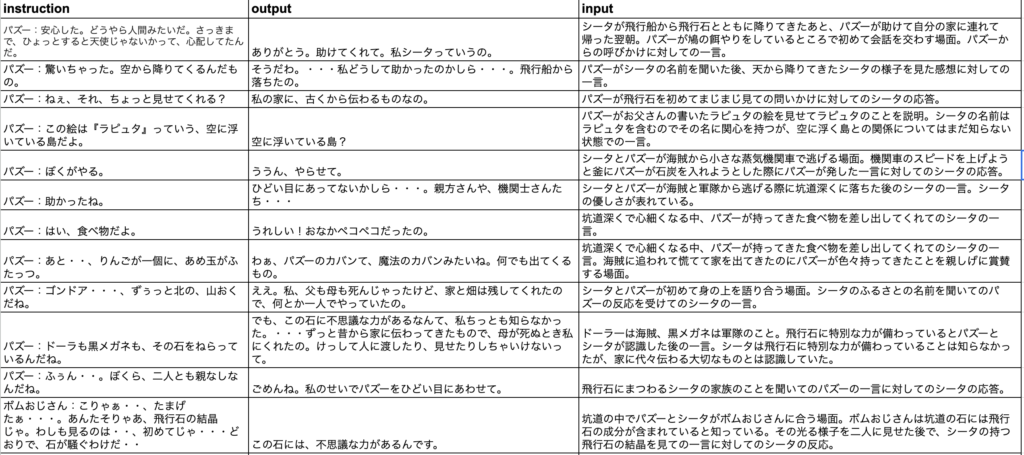
outputがシータのセリフ。instructionはシータのセリフの前のセリフを「人物:セリフ」の形式で整形したテキスト。inputはその会話の場面や背景、心情などを自分なりに解説したテキスト。
実は、ラピュタのセリフは結構擬音が多く、流石に擬音を学習するのは良くないだろうと言うことでちゃんとしたセリフだけを残すと、データ数は55にしかなりませんでした。何かのキャラクターになりきらせるには圧倒的に不十分だとは思いますが、方法・手順を理解するということを目的にLoRAファインチューニングを元ブログと同じくGoogle Colab.で進めていくことにします。Google Colab.を使ったことがない方は、この機会にぜひトライしてみてください。Pythonや機械学習の勉強をするにはとても便利なもので、無料で利用できます。無料枠でGPUも使えます(ただしかなり制限はありますが)。
Google Colab.でのファインチューニング
・Google Colab.の設定
- Googleのアカウントがあれば利用できます。Googleのランディングページ右上のGoogleアプリのボタンをクリックし、Googleドライブを開く。
- 新規+ ボタンをクリックし、一番下のその他を選択すると「Google Colaboratory」が出てくるので選択。左端に三角のプレイボタンがある空の入力枠ができているはず。
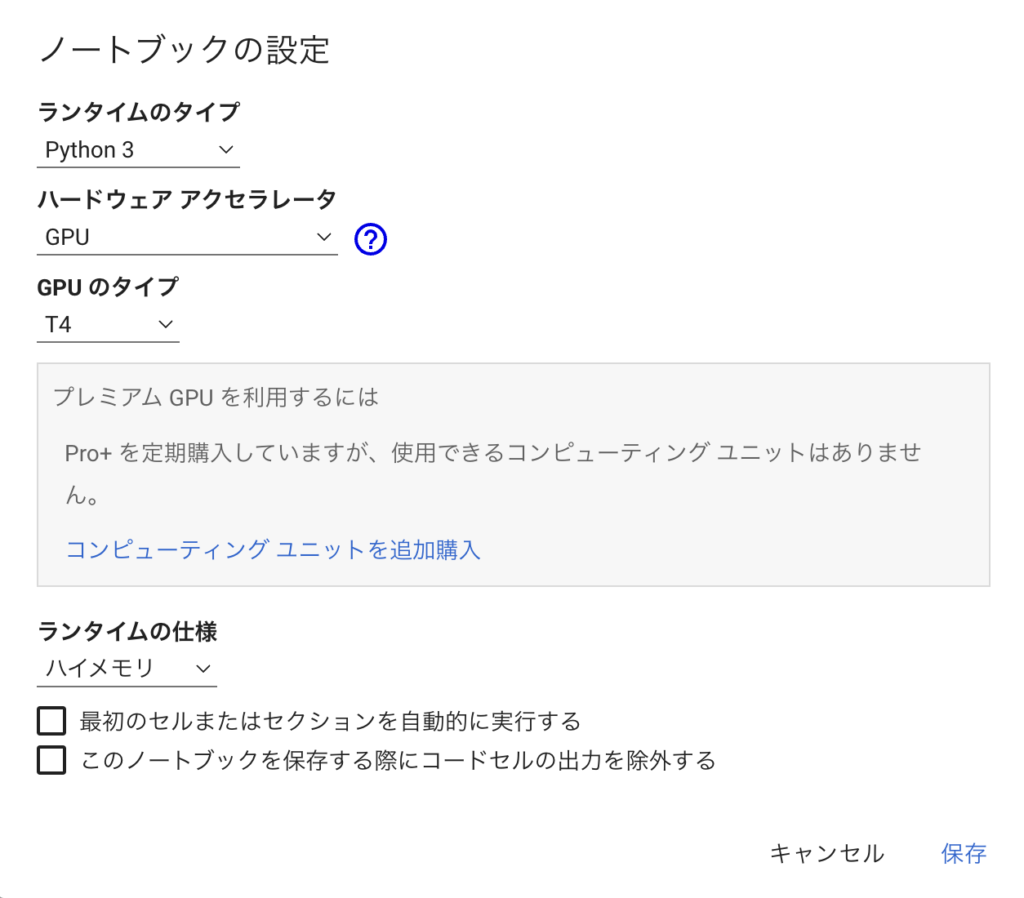
- メニューの「ランタイム」を選択し、「ランタイムのタイプを変更」を選択する。ここで、「ランタイムのタイプ」を「Python3」、「ハードウエアアクセラレータ」を「GPU」→「T4」を選択。「ランタイムの仕様」で「ハイメモリ」が選択できるなら選択。
・いよいよコーディング
入力枠にコードを書いていきます。Google Colab.はインタラクティブにコートど記載して実行できる環境ですので、少しずつコードを書いて確認していくことができます。以下も、ひとまとまりずつ入力枠に書いて、「三角プレイボタン」でコードを実行して、出力やエラーを確認していくのが良いと思います。

以下のコードでGoogle DriveとGoogle Colab.を連携させます。許可を求められますので、指示に従って許可してください。
from google.colab import drive
drive.mount('/content/drive')訓練結果を自動保存するためにワーキングディレクトリを指定しておきます。
import os
os.makedirs("/content/drive/MyDrive/rinna/work", exist_ok=True)
%cd '/content/drive/MyDrive/rinna/work'!pip installで必要なパッケージをインストールしてきます。
!pip install -Uqq git+https://github.com/huggingface/peft.git
!pip install -Uqq transformers datasets accelerate bitsandbytes
!pip install sentencepiece基本パラメータを定義しておきます。最初のmodel_nameで今回訓練する元のモデルを指定します。下の2つはワーキングディレクトリに訓練結果を保存して、推論時に読み出すために自分で適当に決めてください。
model_name = "rinna/japanese-gpt-neox-3.6b"
peft_name = "lora-rinna-3.6b-theta2-peft"
output_dir = "lora-rinna-3.6b-theta2-dir"文字入力をトークン化してコンピュータで計算できる状態にします。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False)
CUTOFF_LEN = 256 # コンテキスト長
def tokenize(prompt, tokenizer):
result = tokenizer(
prompt,
truncation=True,
max_length=CUTOFF_LEN,
padding=False,
)
return {
"input_ids": result["input_ids"],
"attention_mask": result["attention_mask"],
}ファインチューニングデータを学習させるために、モデルに入力する形に整える関数を定義します。
# プロンプトテンプレートの準備
def generate_prompt(data_point):
if data_point["input"]:
result = f"""### 指示:
{data_point["instruction"]}
### 入力:
{data_point["input"]}
### 回答:
{data_point["output"]}"""
else:
result = f"""### 指示:
{data_point["instruction"]}
### 回答:
{data_point["output"]}"""
# 改行→<NL>
result = result.replace('\n', '<NL>')
return resultファインチューニング用のcsvファイルを読み込んできます。pandasで読み込んだ後に、Dadaset形式に変換し、上で定義した関数を適用します。
#元のcsvデータをpandasで読み込んで、訓練データと検証データに振り分ける。今回は全データで55しかないので。訓練データ50、検証データ5とした。
df_load = pd.read_csv("/content/drive/MyDrive/rinna/work/シータdataset.csv")
df_train = df_load.sample(50)
df_val = df_load.drop(df_train.index)
#pandasのデータをDataset形式に変換し、上で定義した関数で訓練用に準備しておく
from datasets import Dataset
train_dataset = Dataset.from_pandas(df_train)
validation_dataset = Dataset.from_pandas(df_val)
train_data = train_dataset.shuffle().map(lambda x: tokenize(generate_prompt(x), tokenizer))
val_data = validation_dataset.shuffle().map(lambda x: tokenize(generate_prompt(x), tokenizer))
dataset = DatasetDict({
"train": train_dataset,
"validation": validation_dataset,
})訓練データの一つを見てみる。
print(generate_prompt(train_dataset[30]))
### 指示:<NL>ムスカ:この石は特別だ。石は持ち主を守り、いつの日にか天空のラピュタへ帰るときの道しるべとして君に受け継がれたんだ。その主人とは、シータ、君のことだ。<NL><NL>### 入力:<NL>ムスカに空から落ちてきた兵士を見せられて、シータの持つ飛行石の意味を聞かされた時のシータの一言。<NL><NL>### 回答:<NL>そんな!あたしなんにんも知りません!・・・石が欲しいならあげます!・・あたし達をほっといて・・・・事前学習済みモデルとPEFTのロード
次からは、モデル訓練の準備
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_8bit=True,
device_map="auto",
)from peft import LoraConfig, get_peft_model, prepare_model_for_int8_training, TaskType
# LoRAのパラメータ
lora_config = LoraConfig(
r= 8,
lora_alpha=16,
target_modules=["query_key_value"],
lora_dropout=0.05,
bias="none",
task_type=TaskType.CAUSAL_LM
)
# モデルの前処理
model = prepare_model_for_int8_training(model)
# LoRAモデルの準備
model = get_peft_model(model, lora_config)
# 学習可能パラメータの確認
model.print_trainable_parameters()import transformers
eval_steps = 10
save_steps = 10
logging_steps = 10
# トレーナーの準備
trainer = transformers.Trainer(
model=model,
train_dataset=train_data,
eval_dataset=val_data,
args=transformers.TrainingArguments(
num_train_epochs=5,
learning_rate=3e-4,
logging_steps=logging_steps,
evaluation_strategy="steps",
save_strategy="steps",
eval_steps=eval_steps,
save_steps=save_steps,
output_dir=output_dir,
report_to="none",
save_total_limit=3,
push_to_hub=False,
auto_find_batch_size=True
),
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),ここまでで、訓練の準備は完了。いよいよファインチューニング本番。
# 学習の実行
model.config.use_cache = False
trainer.train()
model.config.use_cache = True
# LoRAモデルの保存
trainer.model.save_pretrained(peft_name)あっけなく2分ほどで訓練終わり。
Step Training Loss Validation Loss
10 2.405400 1.889686
20 1.783200 1.634742
30 1.624700 1.595681・ファインチューニングモデルでの推論
以下、ファインチューニングしたモデルで推論してみる。
import torch
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
# モデルの準備
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_8bit=True,
device_map="auto",
)
# トークナイザーの準備
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False)
# LoRAモデルの準備
model = PeftModel.from_pretrained(
model,
peft_name,
device_map="auto"
)
# 評価モード
model.eval()# 推論用のプロンプトテンプレートの準備
def generate_prompt(data_point):
if data_point["input"]:
result = f"""### 指示:
{data_point["instruction"]}
### 入力:
{data_point["input"]}
### 回答:
"""
else:
result = f"""### 指示:
{data_point["instruction"]}
### 回答:
"""
# 改行→<NL>
result = result.replace('\n', '<NL>')
return result# テキスト生成関数の定義
def generate(instruction,input=None,maxTokens=256):
# 推論
prompt = generate_prompt({'instruction':instruction,'input':input})
input_ids = tokenizer(prompt,
return_tensors="pt",
truncation=True,
add_special_tokens=False).input_ids.cuda()
outputs = model.generate(
input_ids=input_ids,
max_new_tokens=maxTokens,
do_sample=True,
temperature=0.7,
top_p=0.75,
top_k=40,
no_repeat_ngram_size=2,
)
outputs = outputs[0].tolist()
print(tokenizer.decode(outputs))
# EOSトークンにヒットしたらデコード完了
if tokenizer.eos_token_id in outputs:
eos_index = outputs.index(tokenizer.eos_token_id)
decoded = tokenizer.decode(outputs[:eos_index])
# レスポンス内容のみ抽出
sentinel = "### 回答:"
sentinelLoc = decoded.find(sentinel)
if sentinelLoc >= 0:
result = decoded[sentinelLoc+len(sentinel):]
print(result.replace("<NL>", "\n")) # <NL>→改行
else:
print('Warning: Expected prompt template to be emitted. Ignoring output.')
else:
print('Warning: no <eos> detected ignoring output')これで、たとえば次のように指示すると、シータの回答が返ってくるはずである。。。
generate("パズー:ドーラも黒メガネも、その石をねらっているんだね。")ファインチューニングモデルの検証
3つの質問に対して、8回ずつトライした結果です。ものすごく斬新な回答があって個人的には楽しめましたが、やはり「シータが回答しているかのように」という元々の目論見に対しては惨敗です。
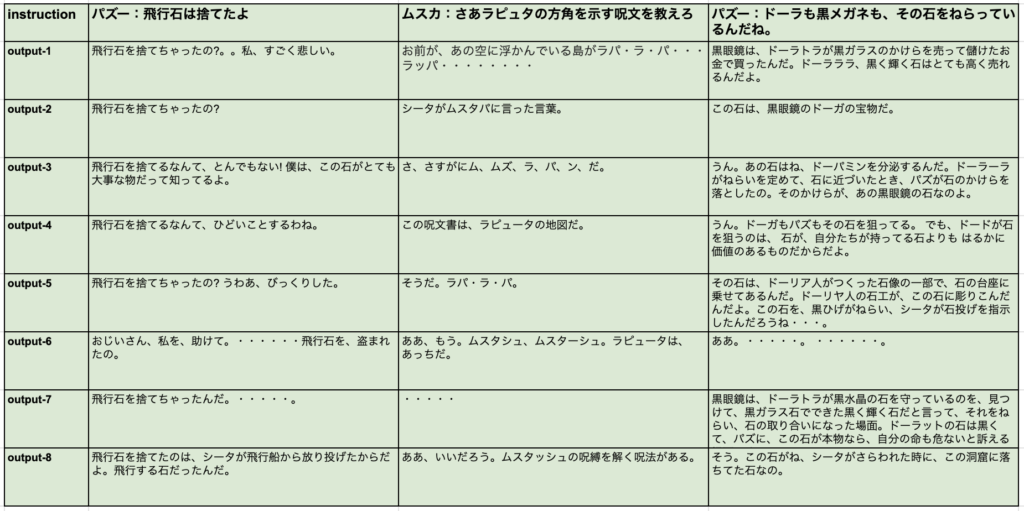
所感
LoRAファインチューニングを自前のデータでやってみましたが、改善の余地が非常に大きいと感じました。問題点としては以下のようなことがあると思います。
- 会話として成立していないことが頻発
- 事実無根の回答
- シータがいいそうもない回答
これら問題点を改良して、ファインチューニングモデルも自らのスキルも磨いていきたいと思います。

